
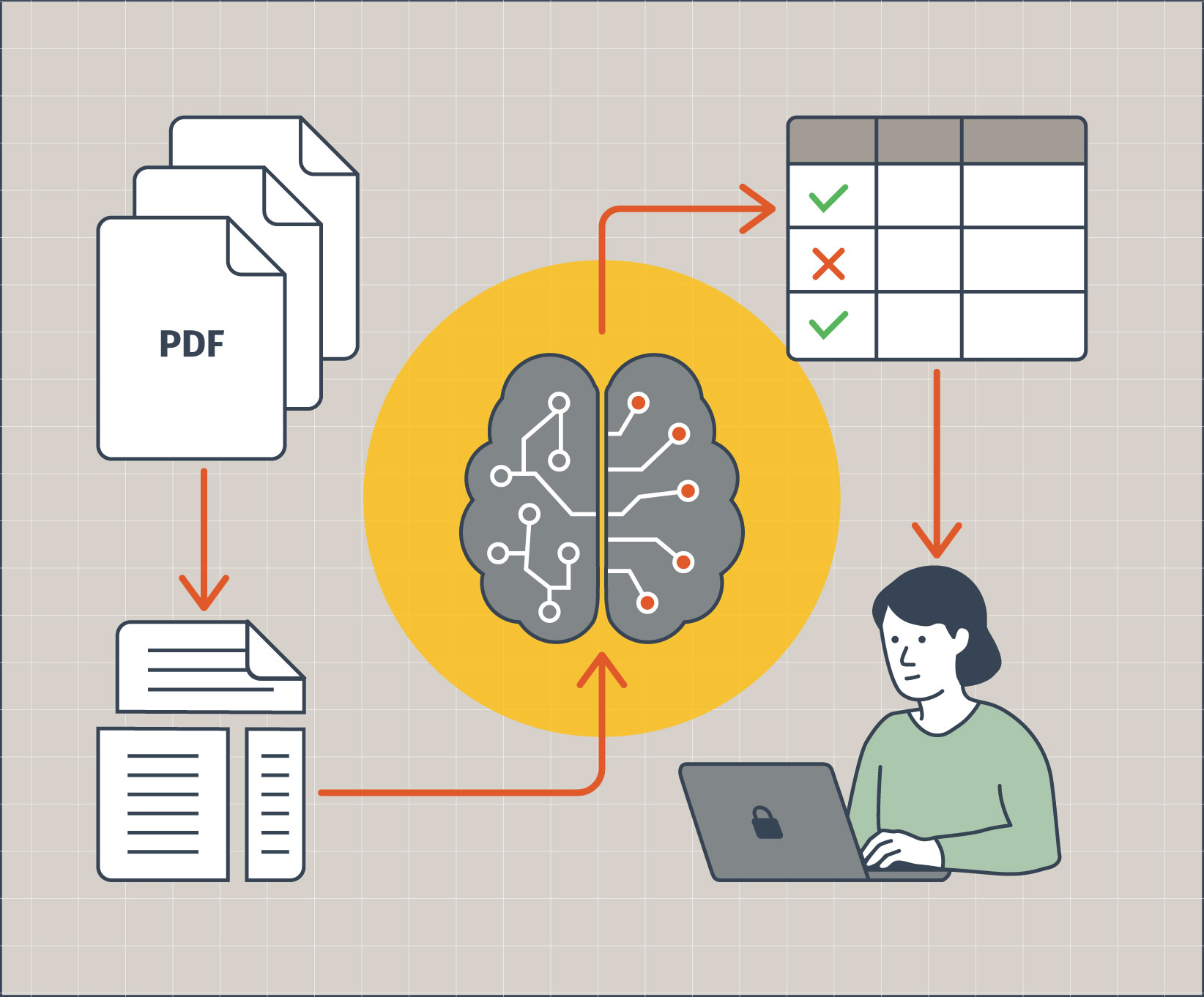
Large Language Models (LLMs) are powerful tools for extracting information from text. However, their tendency to “hallucinate” necessitates careful validation, especially when dealing with critical document processing. We recently came across a challenge that involved the verification of content across numerous documents (think filled-out forms) where accuracy was paramount. Our goal was to create a robust, offline pipeline that leveraged the LLM’s strengths in identifying unstructured content while maintaining human oversight for final verification.
Project Requirements
In this case, we were trying to keep a person from having to manually review hundreds of documents to determine if they contained specific types of unstructured content. We would use LLMs to extract that content and show it to the user, massively speeding up the review process. The LLM would be used to look for the content, but we would then use more classic techniques to validate that the data existed in the document, and provide it to the user for validation.
Only if the content couldn’t be found by the LLM would the document be flagged and a person would then be required to manually review it to determine if the content truly didn’t exist. While full automation would have been preferable, the process had very little tolerance for false positives, so this was determined to be the best approach.
The application needed to:
- Handle diverse document types, but in our case primarily PDFs.
- Utilize a local LLM to determine the presence of categories of content within the pdfs.
- Extract relevant content along with surrounding context.
- Verify extracted content against predefined criteria.
- Isolate and retrieve relevant pages from PDFs.
- Store extraction results in a database for human review.
- Operate entirely offline due to security constraints.
- Ensure high reliability, minimizing false positives and flagging documents requiring thorough human review.
Document Processing Pipeline
The application uses a modular approach to the pipeline, detecting file types and using various libraries to load the appropriate content. As the documents are loaded into a particular folder, they are picked up and handed off to the document pipeline.
The pipeline handles:
- Document loading and preprocessing
- Chunking large documents into smaller pieces
- Extracting content using an LLM
- Verification of extracted content
- Storage of results
Document Loading and Processing
We needed a process for chunking the documents, so that we could analyze individual chunks and use those chunks to gather context around where we found the text we were looking for.
To chunk the documents we use the RecursiveCharacterTextSplitter from langchain.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=settings.CHUNK_SIZE,
chunk_overlap=settings.CHUNK_OVERLAP,
length_function=len,
)
Chunk size needs to be large enough to capture the text we are looking for, and we provide overlap so that we can ensure we don’t miss content split between sections. This can lead to some duplication in findings, but that is easy enough to sort out. There are more involved methods of splitting up documents, but this method got us reasonable results.
Content Extraction
Next we need to extract content from the chunks. To do this we loop over the chunks passing them to the LLM. Again, we use langchain along with a prompt template to do the extraction. Here is a somewhat simplified version of the basic prompt template we are using. The full prompt has more instructions around result formatting and that sort of thing, but this will give you the general idea:
extraction_prompt = f"""
Extract content from the following text based on this instruction: {instruction}
Text to analyze:
{content}
"""
We’re using Ollama as our local LLM provider, which allows us to use various open-source models like Llama or Gemma. It allows us good control over various parameters around temperature, context size, etc… to tweak the behavior of the LLM.
Then to find the content we are looking for, we simply pass it to the LLM. Here we are just passing the completed prompt as a string to the LLM to get a response.
response = llm.invoke(extraction_prompt)
After this we did some additional post processing to ensure that the LLM was giving us back what we were looking for.
Content Verification
Once we found the content we were looking for, we took a second step of asking another LLM to look at the extracted text and score it against our query. To do this, we gave the LLM another prompt that passed the original extraction instructions, a verification prompt, and the extracted text. This is a simplified version of the prompt:
prompt = f"""
You are a verification assistant. Your task is to verify if the extracted text contains the required elements.
Original instruction: {instruction}
Verification criteria:
{verification_prompt_template}
Extracted text:
{extracted_text}
"""
As part of this prompt was also asked the LLM to score it, and gave it a detailed scoring rubric based on the text we were asking it to find.
This two step process was important for reducing potential false positives, and making the extraction more reliable. In theory you could do this in a single step, but splitting it out into a separate step provided better assurances that the LLM was not just verifying against data that it had hallucinated.
This second step was also interesting because we were able to ask the second LLM why it scored it the way it did, and use that to further refine our queries for accuracy.
Storing Extractions
If we found a match, the next step was to store it in the database along with the raw extracted content. This was simply a database record of the document, extracted text, page number, and some other metadata about the extraction.
extracted_content = ExtractedContent(
document_id=document_id,
content_type=content_type,
content_name=content_name,
content=content,
page_number=page_number,
metadata=metadata,
)
db.add(extracted_content)
db.commit()
Future Improvements
There is a ton of opportunity for future improvements of this pipeline. We were using background jobs to process documents, but we could have split those up more to concurrently process the separate chunks for faster processing of the individual chunks.
Additionally we really only needed support for pdf documents, but we could have extended the pipeline to support other document formats, spreadsheets, and that sort of thing. We also extracted images from the pdfs, but for now we weren’t doing anything with them, however we are looking into using other methods to extract image content for additional processing.
The user interface for this was also incredibly straightforward, due to the consumers of this output being engineers. But in the future a more interactive interface could be built to allow less sophisticated consumers of the content to more easily navigate the results.
Conclusion
LLMs show a ton of promise for tasks like this, but they are still somewhat unreliable. Creating a flexible pipeline that validates what it can, while still keeping a human in-the-loop, provided us with a mechanism for greatly speeding up a manual process that took considerable time. As LLM technology continues to evolve, this application could easily be extended with more powerful capabilities.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.



