

I’ll admit that this is a very niche topic (with a very wordy title). Normally, if we’re setting up a database in a test environment, we wouldn’t want to preload data into that database. Only the database structure should be required for our test suite to run, and the tests should be responsible for setting up and tearing down any data that we want to run our code against.
Ideally, if you inherit a project that relies on a lot of seed data to achieve a green CI build, you’d take the time to rewrite the tests so they no longer need the seed data. But, as the Rolling Stones said, you can’t always get what you want. Budget constraints often prevent such a rewrite. So, we work with what we’ve got.
Avoiding GitLFS
Some clients are very cost-conscious. Data packs in GitHub for GitLFS aren’t terribly expensive, but if you can avoid paying for it, why not?
Assuming your seed data file isn’t multiple gigabytes, it’s possible to avoid having to track it with GitLFS. The nice thing about SQL files is that they’re highly compressible. For our example, we have a seed file, testing.sql, that clocks in at 448MB.
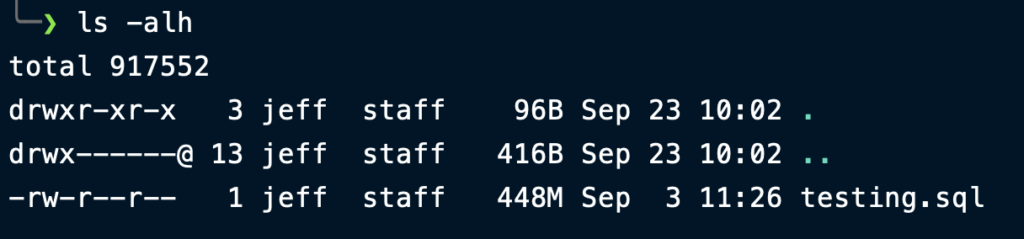
Let’s tar and gzip the file and see what happens:
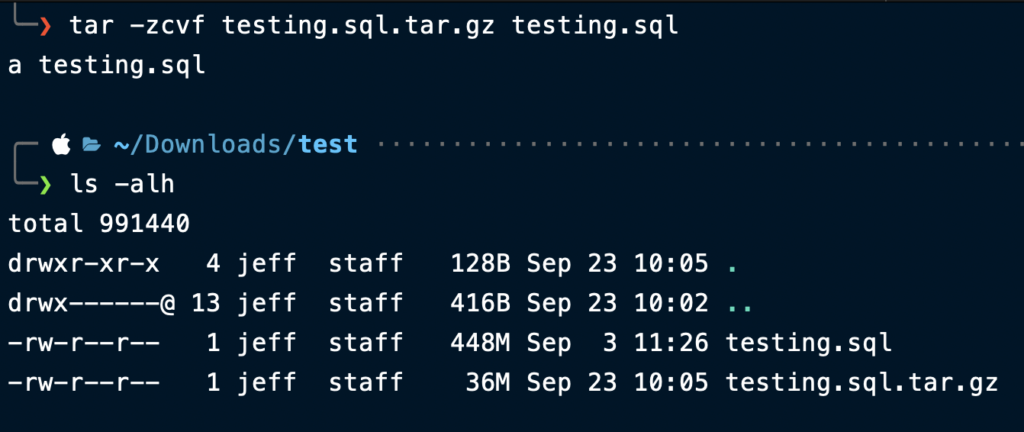
A much more reasonable 36MB! That’s a savings of 92%. Place the gzipped file in a directory in your repository; let’s call that directory test. Use git to commit it to the repository.
Using the compressed SQL in your GitHub Actions workflow
We need to add a step to our workflow that will decompress the gzipped file. This step should happen before you try to run your tests in the CI environment:

Note the use of $GITHUB_WORKSPACE when we’re passing the file name to the tar command. $GITHUB_WORKSPACE is an environment variable that holds the full path to the root of your repository in the GitHub Actions runner container. We’re also using it to pass the target directory where we want the file to be decompressed to.
You can now use the file at $GITHUB_WORKSPACE/test/testing.sql to seed your database.
[record scratch] “No space left on device”
Okay, I lied. If you try to load a SQL file of that size into Postgres, you’re going to get an error message saying that there’s “no space left on device.” The actual issue is a lack of swap space available to your Postgres service container, but the fix is simple (though not well documented).
To change the amount of available swap space, you need to set the shm-size (shared memory size) option. That looks something like this:
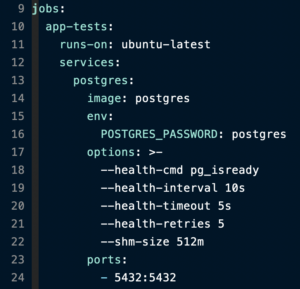
Set it to a value larger than the size of your decompressed seed file. In this case, our decompressed seed file is 448MB, so I’ve set the shared space to 512MB.
Commit these changes to your workflow, and your database will be properly seeded in the next build.
Is this a perfect solution? Nope. Will it get your tests running in CI until you can properly address the issue? It sure does. Just remember to put a card in the backlog to pay down this technical debt in the future.
Loved the article? Hated it? Didn’t even read it?
We’d love to hear from you.



